Optimización de intervenciones
automatizadas contra discursos
de odio en redes sociales
Carrera de Especialización en Inteligencia Artificial · CEIA FIUBA
Director: Dr. Juan Manuel Ortiz de Zarate (FCEyN-UBA)
Jurado:
Esp. Lic. Noelia Melina Qualindi (FIUBA) — [email protected]
Esp. Ing. Diego Martín Braga (FIUBA) — [email protected]
Dr. Ing. Facundo Lucianna (FACET-UNT / FIUBA) — [email protected]
Ciudad Autónoma de Buenos Aires, abril de 2026
El problema
Normsy
- Iniciativa no partidaria, sin fines de lucro
- Desarrollada por Data Voices para Civic Health Project (EE.UU.)
- En producción desde enero 2023
- Dos modos: human pilot + LLM copilot y full automatizado
publica intervención · recolecta métricas de engagement
Ene 2023
Normsy en
producción
Ene 2024
Cuentas humanas
operativas
2024–2025
Pipelines de datos
y framework
Q3 2025
Cuentas
automatizadas
2025–2026
Fine-tuning
y evaluación
Abr 2026
Defensa
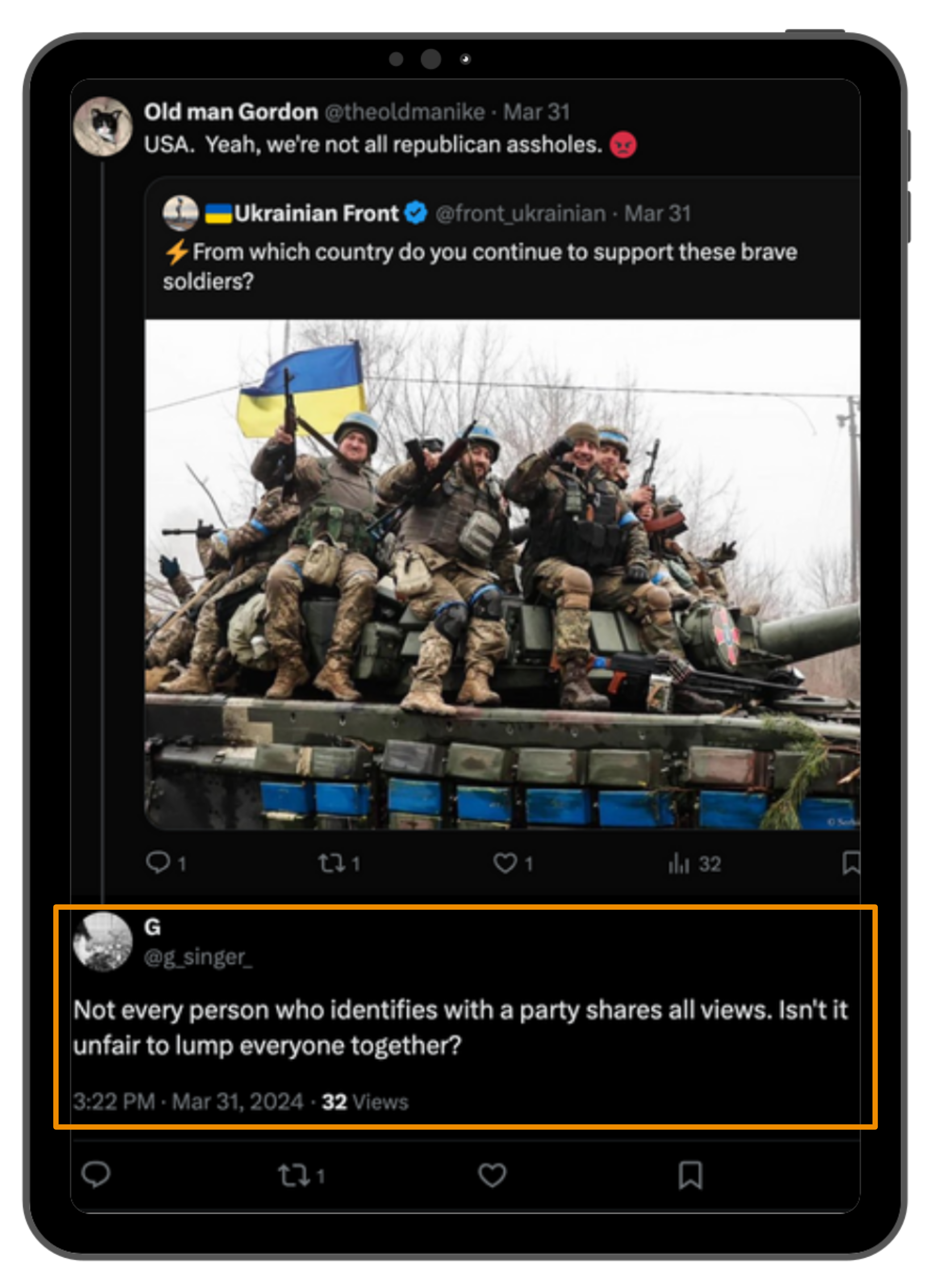
Normsy en acción
Recorrido: tweet tóxico detectado → clasificado → intervención publicada
Flujo
de
intervención
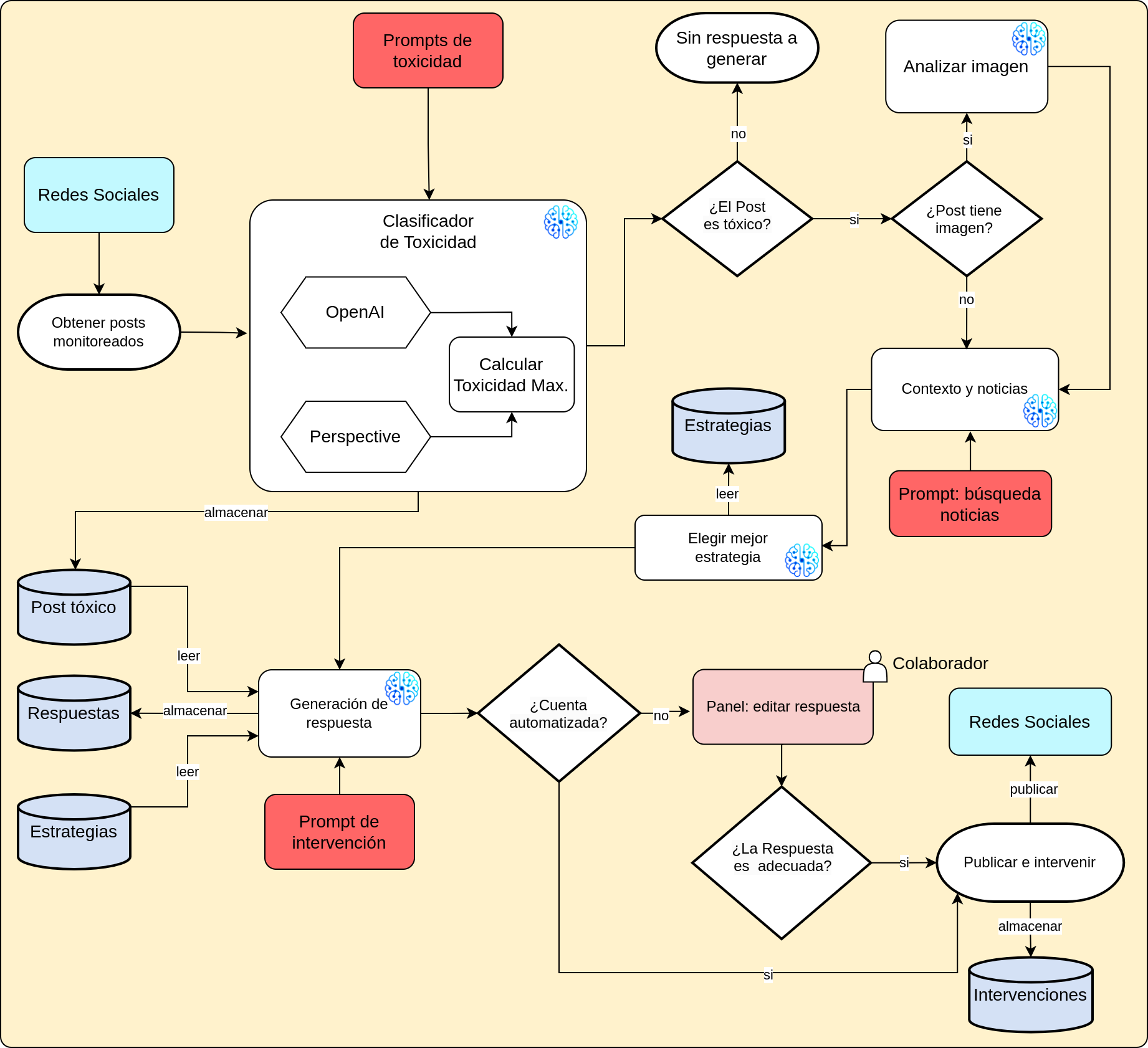
Solución de datos — el problema
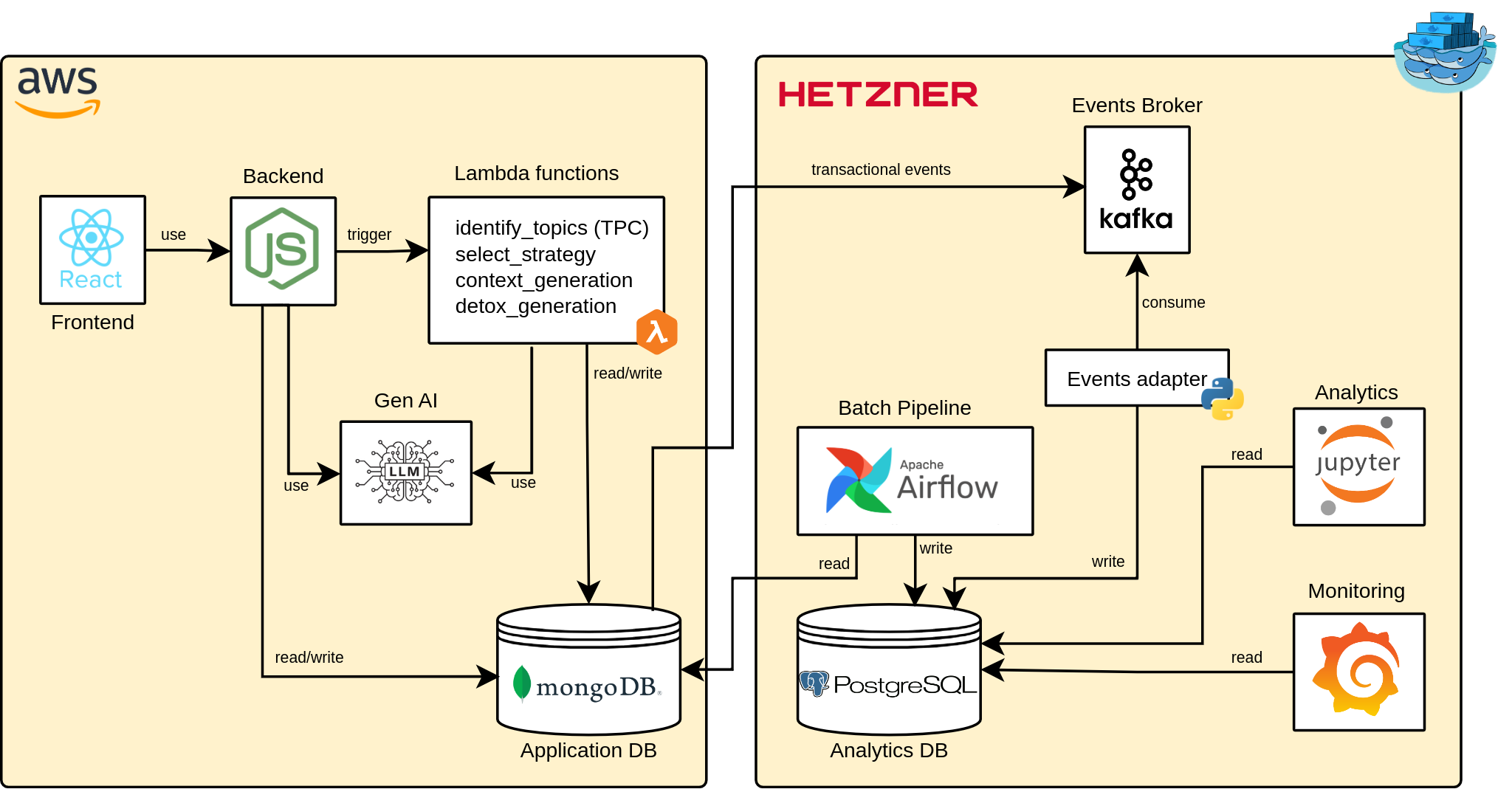
Decisión de diseño
MongoDB → PostgreSQL
Esquema relacional en Hetzner
Patrón CQRS — lectura y escritura separadas
Grafana + Jupyter sobre PostgreSQL
Sin impacto sobre la base transaccional
Dos estrategias de procesamiento

Change Data Capture — pipeline en Normsy
Latencia end-to-end: < 1 segundo
Sin impacto sobre la base transaccional

Análisis exploratorio — cuentas automatizadas

el volumen acumulado por cuentas humanas desde 2024

→ el escalado no degrada la calidad individual

→ las intervenciones generan interacción real
Clasificador de toxicidad — el problema
Falsos positivos
Post no tóxico clasificado como tóxico
→ intervención innecesaria publicada en X.com
→ fricción pública, erosión de credibilidad
Impacto operacional
Recursos de inferencia desperdiciados
Generación de respuestas contraproducentes
Riesgo reputacional para la plataforma
Precisión — baseline producción (escala 0–10)
0,396≈ 1 de cada 2,5 intervenciones
se activa sobre contenido no tóxico
Framework de evaluación de clasificadores
- 13 modelos de 5 proveedores
- Escalas: 0–10, 0–3 y binaria
- Métricas: F1, precisión, recall, costo USD, latencia
- Dataset golden: 400 posts (100 por clase)
YAML
Configuración
de experimento
CLI
run.py
punto de entrada
LLM APIs
OpenAI · Google
Anthropic · xAI · Alibaba
PostgreSQL
Resultados
y métricas
Framework — configuración de experimentos
test: name: "Multi-Provider Toxicity Classification" dataset: name: "ground_truth" models: - name: "gemini-2.5-flash" # Google - name: "gpt-4.1-2025-04-14" # OpenAI - name: "grok-4-fast-non-reasoning" # xAI - name: "claude-haiku-4-5" # Anthropic - name: "qwen-flash" # Alibaba ... (13 modelos total) prompts: - name: "toxicity_3_prod.jinja2" - name: "toxicity_3_alternative.jinja2" - name: "basic_tox_notox_0_3.jinja2" settings: retry_attempts: 3 prompt_scale: [0, 3]
① CLI
Lee YAML
② Dataset
Carga golden
③ Clasificación
modelo × prompt
④ Métricas
F1, precisión, recall
⑤ Persistencia
PostgreSQL
Plataforma en acción
Dashboards Grafana · pipeline ETL · CDC Kafka · métricas en tiempo real
Evolución de la escala de clasificación

Selección de modelo — frontera de Pareto
Modelos sobre la frontera:
- grok-4-fast-non-reasoning
- gemini-2.0-flash
- gemini-2.5-flash-lite
- qwen-flash

El problema: precisión baja en modelos base

¿Puede el fine-tuning
mejorar la precisión?
El framework detectó que todos los modelos base tienen baja precisión.
Hipótesis: ajustar un modelo con datos del dominio puede reducir
los falsos positivos y mejorar el rendimiento general.
Fine-tuning — Vertex AI
| Versión | Modelo base | Escala |
|---|---|---|
| v1 | gemini-2.5-flash | 0–3 |
| v2 | gemini-2.5-flash-lite | 0–3 |
| v3 | gemini-2.0-flash-001 | 0–3 |
| v4 | gemini-2.5-flash | Binaria |
Técnica: LoRA (Low-Rank Adaptation)
Cada versión: endpoint dedicado en Vertex AI
La solución: fine-tuning mejora la precisión

Resultados comparativos
| Configuración | Mejor modelo | F1 | Precisión | Recall |
|---|---|---|---|---|
| 0–10 | gemini-2.5-flash | 0,529 | 0,409 | 0,749 |
| 0–3 (sin SFT) | gemini-2.5-flash-lite | 0,611 | 0,465 | 0,891 |
| 0–3 SFT v3 | sft_gemini-2.0-flash:v3 | 0,604 | 0,649 | 0,565 |
| Binaria (prompt base, sin SFT) | gemini-2.5-flash | 0,714 | 0,654 | 0,785 |
Hallazgos
Prompt binario: alternativa de menor costo operacional con rendimiento comparable al SFT actual
Impacto en producción
Resultados presentados en tres instancias al equipo de Civic Health Project — decisiones concretas adoptadas:
① Cambio de escala
Migración de clasificación 0–10 → 0–3 en producción
② Selección de modelo
Familia Gemini adoptada como clasificador de producción
③ Escalado automatizado
Despliegue de cuentas automatizadas → 111.000+ intervenciones publicadas
Conclusiones
- Pipeline analítico habilita por primera vez análisis histórico sistemático.
- Cuentas automatizadas escalan volumen sin degradar calidad individual.
- Escala 0–10 → 0–3: mejora consistente en todos los modelos.
- SFT mejora precisión en +64 % vs baseline.
- Prompt binario: alternativa competitiva sin entrenamiento.
Próximos pasos
① Dataset — escalar el conjunto de ajuste para convergencia del SFT.
② DPO — Direct Preference Optimization para balance precisión/recall más controlado.
③ Embeddings multimodales — LLM → embeddings → SVM/XGBoost, elimina costo de inferencia por post.
Muchas gracias
¿Preguntas?
Mg. Ing. Joaquín González · CEIA FIUBA · Abril 2026